
Connecting SwiftUI and Cloud Firestore
Replicating the iOS Reminders App, Part 2
This article is part of a series of articles that explores building a real-world application using SwiftUI, Firebase, and a couple of other technologies.
Here is an overview of the series and what we’re going to build:
- In part 1 of the series, we focussed on building the UI with SwiftUI, using a simple data model.
- In part 2 (which you are reading right now), we’re going to connect the application to Firebase, and will synchronize the user’s tasks with Cloud Firestore
- In part 3, we will implement Sign in with Apple to turn the application into a real multi-user application
In the previous article of this series, we saw how easy it was to replicate the UI of a well-known iOS app using SwiftUI: writing very little code, we implemented a fully functional copy of the iOS Reminders app. To keep things simple, we persisted data on the user’s device using the Disk framework.
Today, we’re going to look into what’s required to connect this app to Firebase, allowing users to store their data in the cloud.
There are many reasons for storing data in the cloud: your users might want to access their data from multiple devices, such as their phone and their tablet. Or, they might want to share data with their coworkers or family and friends.
Sounds complicated and like a lot of work? Well, fear not - all of this is possible with Firebase and Cloud Firestore, and as you will see in this article, it’s not even very complicated.
So, let’s get started!
Setting up Firebase
If you’re following along, check out the tag
stage_3/implement_firestore_repository/start
and open MakeItSo.xcworkspace in the final folder.
To use Firebase in your app, you’ll have to set up a Firebase project and connect your app to it. It takes just a few steps:
- Set up a new Firebase project with the Firebase console on the web
- Add the Firebase SDK to your app (I recommend using CocoaPods, as we’re already using this to integrate other libraries such as the Disk framework)
- Download the
GoogleService-Info.plistconfiguration file which tells the Firebase SDK which of your Firebase projects to connect to - Import Firebase into your code and initialise it in your application delegate
target 'MakeItSo' do
use_frameworks!
# Pods for MakeItSo
pod 'Resolver'
pod 'Disk', '~> 0.6.4'
pod 'Firebase/Analytics'
pod 'Firebase/Firestore'
pod 'FirebaseFirestoreSwift'
endRemember, we added Resolver and Disk in part of this series.
Coincidentally, I just created a short video that explains how this works in more detail:
What is Cloud Firestore, anyway?
Let’s quickly review what Cloud Firestore is to understand why it is a good fit for our project.
The product website says that “Cloud Firestore is a NoSQL document database that lets you easily store, sync, and query data for your mobile and web apps - at a global scale.”
That sounds great, so let’s take a look at some of Cloud Firestore’s properties to better understand what all of this means:
- It is a NoSQL document database, which means that your data doesn’t have to follow a schema you might know from a traditional SQL database like MySQL. This makes it easier to upgrade your data model without having to migrate all your existing data to a new schema.
- You can structure your data in collections and documents, making it easy to organise your data hierarchically. For example, you can store all the user’s tasks in one collection, making it convenient to retrieve all their tasks or just a few, based on some criteria you define.
- Your users can make changes to their data even when offline, and all of their updates will get synchronised across all of the user’s devices automatically.
- Cloud Firestore provides SDKs for popular programming languages and environments such as iOS, Android, and the web.
For more details, check out this video:
Mapping our data model to Cloud Firestore
Mapping our data model to Cloud Firestore is pretty straightforward, and thanks to the recently added support for Codable, we won’t even have to make many changes to our existing code base.
In Cloud Firestore, you store data in documents. You can think of a document as a lightweight record that contains fields which map to values. Each document is identified by a unique name. Each field has a type, such as string, number, boolean, or more complex ones like map, array, and timestamp - see the documentation for a discussion of their specifics, such as value ranges and sort order.
Documents are stored in collections. For example, you could have a tasks collection to contain all of your tasks.
Hierarchical data model
Collections contain nothing but documents - you cannot store data directly into a collection. Similarly, documents cannot contain other documents, but they can point to subcollections, which in turn contain other documents. This allows you to build a hierarchical data model.
For a task list application that wants to support multiple lists per user, the most straightforward approach might be to build a hierarchical data model that looks like this:
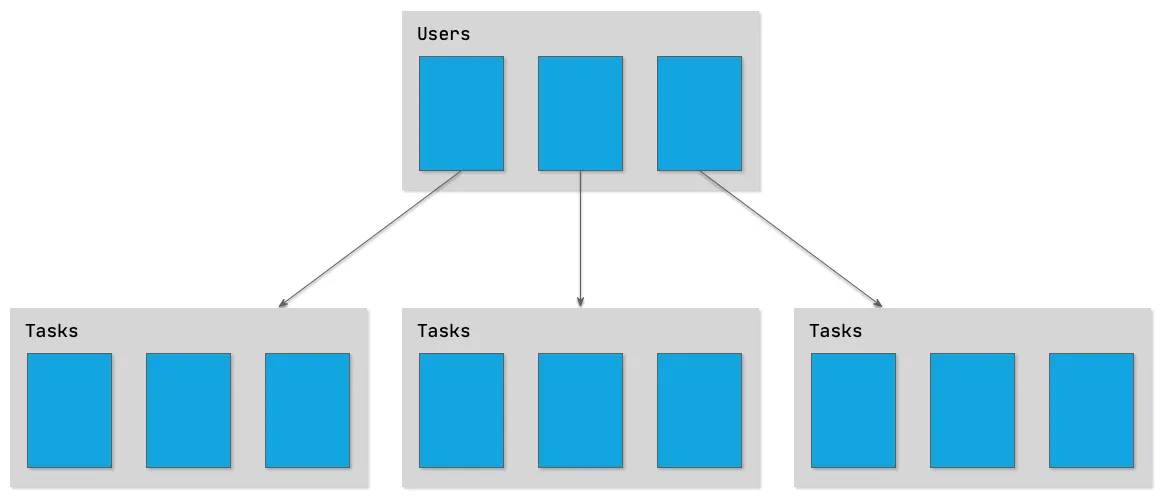
While this certainly works (and actually was the approach used in an earlier version of the app we’re building), it will make things more challenging in the long run. Let’s consider two use cases that we might want to implement in the future:
-
Supporting multiple lists per user: At first sight, this looks very simple: create a collection for each list, and put all tasks on that list into the corresponding collection. However, this structure will make it more difficult to run a query that yields all the user’s tasks across all lists that have been completed in the past week (something you might want to know when creating a report).
-
Sharing lists with friends: In our hypothetical hierarchical data model, a user’s lists would be nested under the user’s ID. This would make sharing lists with other users very complicated - you’d have to come up with some sort of “proxy” lists that point at the original list. Reasoning about how to retrieve lists and tasks would become a lot more complicated than it needs to be.
Flat data model
Instead of using a hierarchical data model, let’s use a flat data model and store all tasks in a single tasks collection. To specify ownership, we will store the user ID of the owner in the task document. When retrieving a user’s task, we can then simply query for all tasks that match the user’s ID.
Supporting advanced use cases becomes a lot easier now:
-
To support multiple lists per user, we will create another collection containing all lists (again using a
userIdfield to specify list ownership). To assign a task to a list, all we need to do is store the list ID in a fieldlistIdin the task document, which makes it simple to search for all tasks in a particular list. -
Likewise, sharing lists with friends becomes rather simple as well: again , each list has a field userId to indicate the owner. To share a list with other users, we can add another field sharedWith that contains a list of user IDs this list is shared with.
Check out this video for a discussion of some of how to structure your data in Cloud Firestore:
Here is how this would look like conceptually:
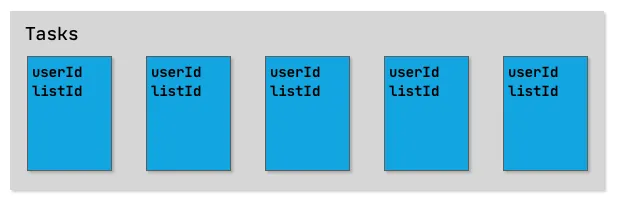
In the introduction to this series, we decided to deliberately simplify the application a bit - for example, we only support one list per user in the first iteration. The good news about our data model is that it is perfectly suitable for the simplified version of the app, while still being future proof: adding support for multiple lists per user is something that our data model can handle. We will update the UI to support multiple lists in a later part of the series.
Now that we have a good understanding of how the overall structure of our data model looks like, let’s take a look at the changes we have to make to our source code to implement this.
// File: Models/Task.swift
import Foundation
import FirebaseFirestore 1
import FirebaseFirestoreSwift
enum TaskPriority: Int, Codable {
case high
case medium
case low
}
struct Task: Codable, Identifiable {
@DocumentID var id: String? 2
var title: String
var priority: TaskPriority
var completed: Bool
@ServerTimestamp var createdTime: Timestamp? 3
}As promised earlier, there are just a few changes:
- We need to import
FirebaseFirestore(1) andFirebaseFirestoreSwift(which contains support for Swift Codable) - Every Firestore document (and every collection) has a unique identifier. We can make use of this fact and map this to our
idfield (remember we need to help theListview to track the individual rows, e.g. when inserting or deleting elements from the list). The@DocumentIDproperty wrapper (provided byFirebaseFirestoreSwift) tells Firebase to map the document’s ID (the last part of the document path) to this property when decoding the document. - Likewise,
@ServerTimestamptells Firestore that it should write the current server timestamp into this field when writing the document into the database. Using a server-side timestamp is important when working with data that originates from multiple clients, as the clocks on the clients are most likely not in sync with each other. We will later use this field to ensure that the data is displayed on the client in the order in which it was added to the list.
Implementing the Repository
In the first part of the series, we used the Disk framework to persist data to … disk. We also used dependency injection to decouple the view models from the repository and thus make it easier to swap out the repository implementation. As you will see in a minute, this allows us to change the persistence technology without having to change any of the views or view models.
Let’s walk through the implementation of the new repository feature by feature.
Fetching Tasks from Firestore
One of the key features of Firebase is its near-real-time nature: clients can specify they’d like to be notified for any changes to a document or multiple documents. To do so, you’ll have to register a snapshot listener on the document or a query (to be notified when any of the documents in the result set of the query changes). All of this happens almost instantly (depending on the quality of your network connection).
If you don’t care for real-time updates, you can also perform a one-time fetch.
For our application, we are interested in real-time updates, as this will allow us to let the user use multiple devices to manage their data without having to worry about synchronising data manually (or implementing any pull-to-refresh functionality).
To receive updates for the user’s tasks, we simply register a snapshot listener on the tasks collection.
// File: Repositories/TaskRepository.swift
class FirestoreTaskRepository: BaseTaskRepository, TaskRepository, ObservableObject {
var db = Firestore.firestore() 1
override init() {
super.init()
loadData()
}
private func loadData() {
db.collection("tasks").order(by: "createdTime").addSnapshotListener { (querySnapshot, error) in 2
if let querySnapshot = querySnapshot {
self.tasks = querySnapshot.documents.compactMap { document -> Task? in 3
try? document.data(as: Task.self) 4
}
}
}
}
// more code to follow
}A few things are worth pointing out:
- We keep a reference to the global Firestore instance (1). For the Firestore client SDK to know which database to connect to, Firebase needs to be properly initialised. We did this when we first added Firebase to the project. If you haven’t copied
GoogleService-Info.plistto the project and calledFirebaseApp.configure()in your application delegate, go back and watch that video I linked earlier in this article. - The canonical way to register a snapshot listener is
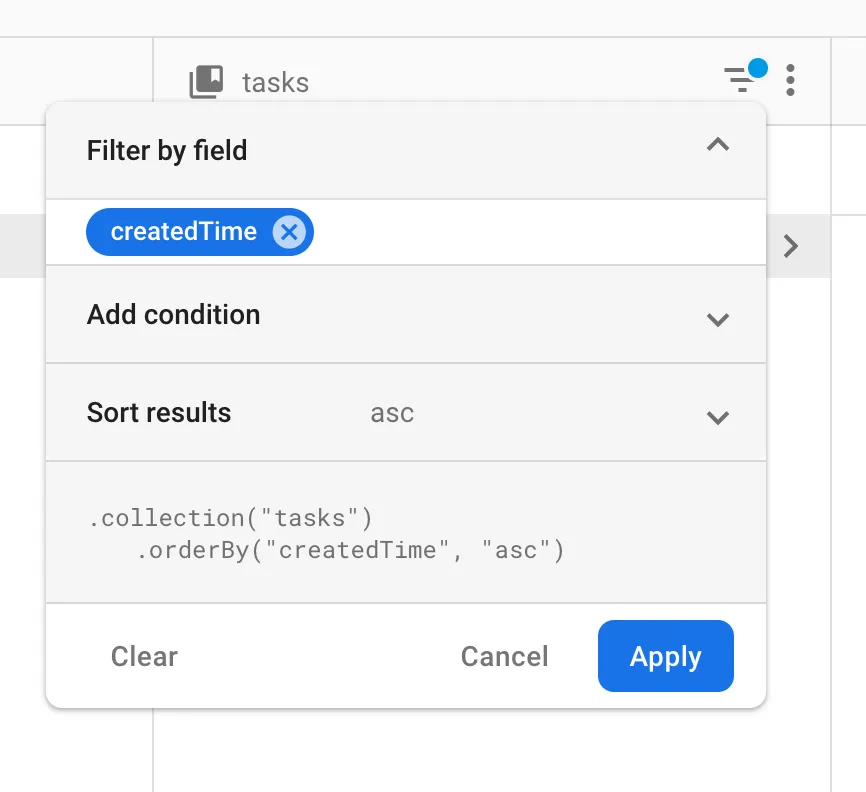
db.collection("path").addSnapshotListener(callback). In this snippet (2), I insertedorder(by: "createdTime")- why? By default, a query retrieves all documents that satisfy the query in ascending order by document ID. This means they will appear in ourListview in exactly this order, which is not what we want: document IDs are globally unique random strings which will result in random order. As we want to make sure that the tasks the user enters in the UI appear in exactly the order they add them, we’ll use a server-side timestamp to order them chronologically. You can experiment with different order clauses and filters in the Cloud Firestore UI - see the following image:
- The
querySnapshotwe receive in the closure contains a collection of all the documents that are a result of the query (as we didn’t specify any conditions, we will receive all documents in the tasks collection). UsingmaporcompactMap(3), we can transform the elements of this collection intoTasks. - Right now, this query will try to grab all tasks from all users, no matter who wrote them! This is obviously a major problem, which we’ll be fixing later in this post.
- Thanks to Firestore’s support for
Codable, converting a FirestoreDocumentSnapshotinto aTaskis a one-liner (4). As the result of this call is an optional, and might benil(e.g. when there was a problem performing the mapping due to non-matching data types), we need to usecompactMapwhen iterating over the collection. This will ensure we only return non-nil elements from the closure, thus yielding a result of[Task](as expected), rather than[Task?].
Adding New Tasks to Firestore
To add a new document to a Firestore collection, it is sufficient to call addDocument() on the collection. Firestore’s support for Codable makes this a delightfully simple call, as we can just pass in any struct or class that implements Codable. In the past, you’d have to convert your object into a dictionary first.
Here is the complete code for adding a new task:
class FirestoreTaskRepository: BaseTaskRepository, TaskRepository, ObservableObject {
// ... more code omitted for clarity
func addTask(_ task: Task) {
do {
let _ = try db.collection("tasks").addDocument(from: task)
}
catch {
print("There was an error while trying to save a task \(error.localizedDescription).")
}
}
// ... more code omitted for clarity
}You might be wondering why we didn’t add the new task to the local tasks property. Firestore will call the snapshot listener we’ve registered on the tasks collection immediately after making any changes to the contained documents - even if the application is currently offline. This means that the closure in loadData() will be called shortly after we’ve added a new task, and thus update the tasks property. This means we don’t need to bother updating the property inside addTask() or any of the other methods that operate on the user’s tasks.
Updating an Existing Task in Firestore
Once the user updates a task by tapping on the task’s checkbox or changing its title, we want to send those updates to Firestore as well.
Updating a document in Firestore requires knowing its path and document ID. Since we asked Firestore to map the document ID to the id field of our Task struct, we already have the document ID:
class FirestoreTaskRepository: BaseTaskRepository, TaskRepository, ObservableObject {
// ... more code omitted for clarity
func updateTask(_ task: Task) {
if let taskID = task.id {
do {
try db.collection("tasks").document(taskID).setData(from: task) 1
}
catch {
print("There was an error while trying to update a task \(error.localizedDescription).")
}
}
}
// ... more code omitted for clarity
}Again, it’s really easy to update the document, thanks to Firestore’s Codable support (1): just call setData(from:) - it’s that simple.
Deleting a Task from Firestore
Finally, let’s look at how to delete tasks from Firestore:
class FirestoreTaskRepository: BaseTaskRepository, TaskRepository, ObservableObject {
// ... more code omitted for clarity
func removeTask(_ task: Task) {
if let taskID = task.id {
db.collection("tasks").document(taskID).delete { (error) in 1
if let error = error {
print("Error removing document: \(error.localizedDescription)")
}
}
}
}
// ... more code omitted for clarity
}We first build a reference to the document, using the collection path (tasks) and the document’s ID. Deleting the document then is as easy as calling delete() on the document reference.
Wiring up the Repository
To try out the new repository, we need to register it with our dependency injection framework, Resolver:
// File: App/AppDelegate+Injection.swift
import Foundation
import Resolver
extension Resolver: ResolverRegistering {
public static func registerAllServices() {
register { FirestoreTaskRepository() as TaskRepository }.scope(application)
}
}Before you can run the application, we need to make provision a Firestore database in our Firebase project. To do so, go to the Firebase Console and navigate to the database section of your project and click on “Create database” to create a Firestore database for your project:

When asked about security rules, choose “Start in test mode”. Later on, we will need to update the security rules to properly secure the database. For now, your database is open for everyone to read and write. To minimize the risk, this full access expires one month into the future (and you will receive some increasingly nagging emails shortly before this time runs out).
Now, run the application on a Simulator or your phone. Initially, you should see an empty list. Go ahead and add a couple of tasks (keep in mind you need to tap the enter key to commit them), mark some of them as done, and update others.
To better understand what’s going on, open the Firebase Console in your browser navigate into the database section of your app. You should see something similar to this:
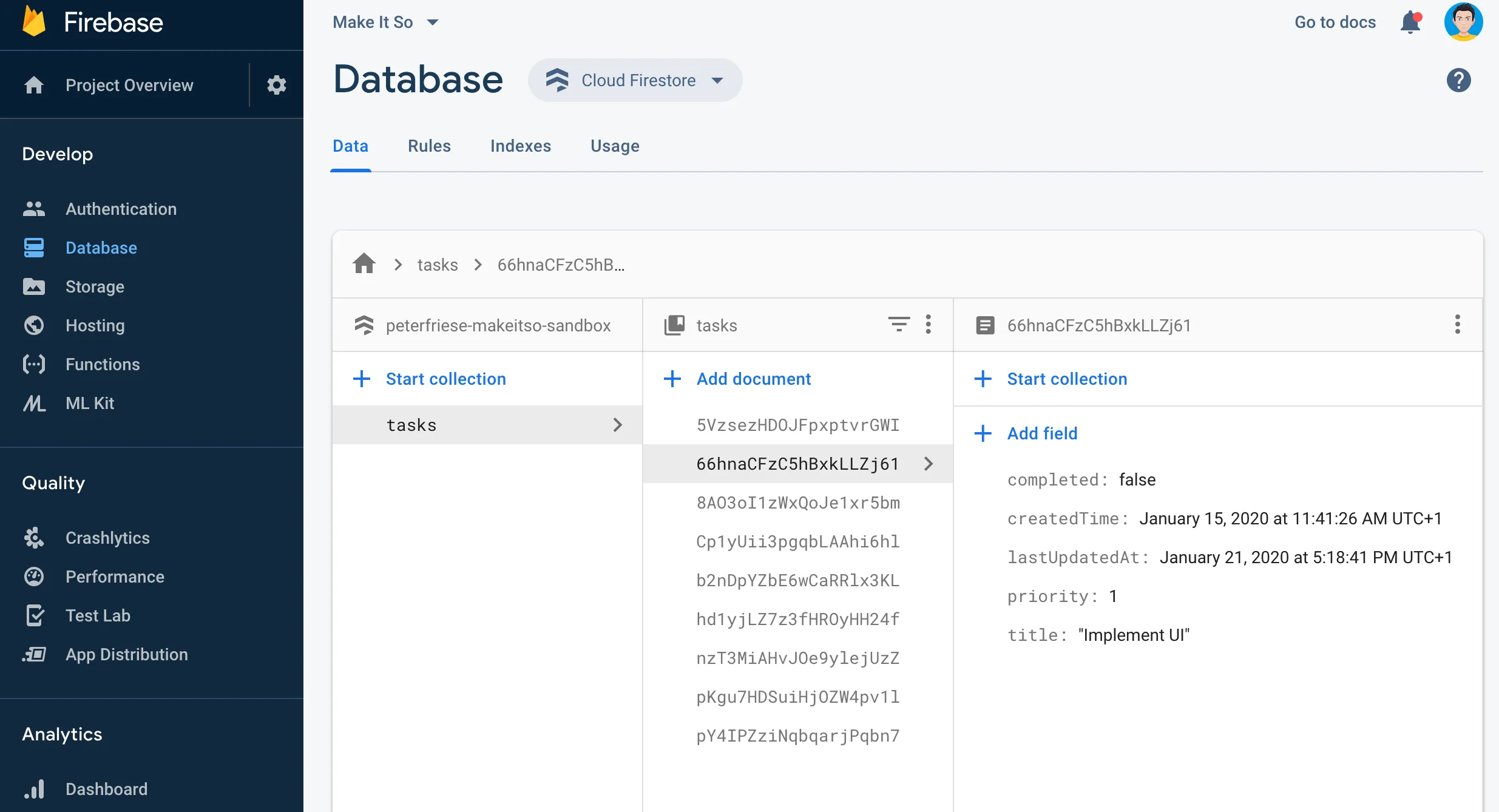
You will notice how the data in the database browser gets updated almost instantaneously as you update the tasks in your app. Now go ahead and update a task by editing it in the database browser - as soon as you save the change, it will be reflected in the app! Take it a step further by starting the app on two devices (or a Simulator and a physical device) and try the same - the data stays in sync across all instances. Nice, huh?
But what about multiple users?
By now, you’re probably wondering how we’re going to support multiple users. After all, when we talked about the data model, we did mention multiple users, right? As it stands, the current implementation will use the same Firestore collection for all users - so all users will have to share their tasks. This is not what we want.
Ultimately, we will need to implement a way for users to create an account and sign in to the app. Authentication systems usually have some form of user ID that can be used to organise the user’s data. If you recall our earlier discussion of the data model for our application, you’ll remember that we were going to add a field userId to each task document to refer to the user who “owns” this piece of data.
Asking users to create a user account does have advantages (for example, this is a prerequisite to sharing data with other users of your app), but it might also be a roadblock: if your users have to sign up for an account before being able to start using your app, they might decide to not give your app a try and uninstall it instead. The drop-off numbers can be significant. Thankfully, there is an easy way to avoid this (and pave the way for using a full-blown authentication system later on): Firebase Anonymous Authentication.
Signing in Anonymously
Firebase Anonymous Authentication lets you sign in your application’s users without asking them to provide any information about themselves - hence anonymous. The whole process is completely transparent, which eliminates any sign-up speedbump that your users would face otherwise.
You can later provide opportunities for them to create a full user account (e.g. by signing in with Google, Facebook, Twitter, or Sign in with Apple), enabling more advanced functionality such as sharing data with other users. Firebase Authentication makes upgrading anonymous users to a full user very easy - we will take a look at how this works in the next episode of this series.
Like any Firebase user, anonymous users have a unique user ID, which allows us to uniquely identify them and store user-specific data, keeping it safe from other users’ eyes. Firebase Security Rules provide a powerful way to protect user data, making sure only the owner of the data can see it and perform operations on it.
To support Firebase Anonymous Authentication in your application, you need to follow these steps:
- Turn on support for Anonymous Auth in the Firebase Console
- Add the Firebase Auth pod to your project
- Perform an anonymous sign in at application start-up
- Use the anonymous user’s ID to store/retrieve data
If you’re following along, check out the tag
stage_3/implement_anonymous_auth/start
and open MakeItSo.xcworkspace in the final folder.
To enable support for Anonymous Authentication, navigate to the Authentication section in the sidebar of your Firebase project, and open the Sign-in method tab. Turn on Anonymous, and click the Save button.
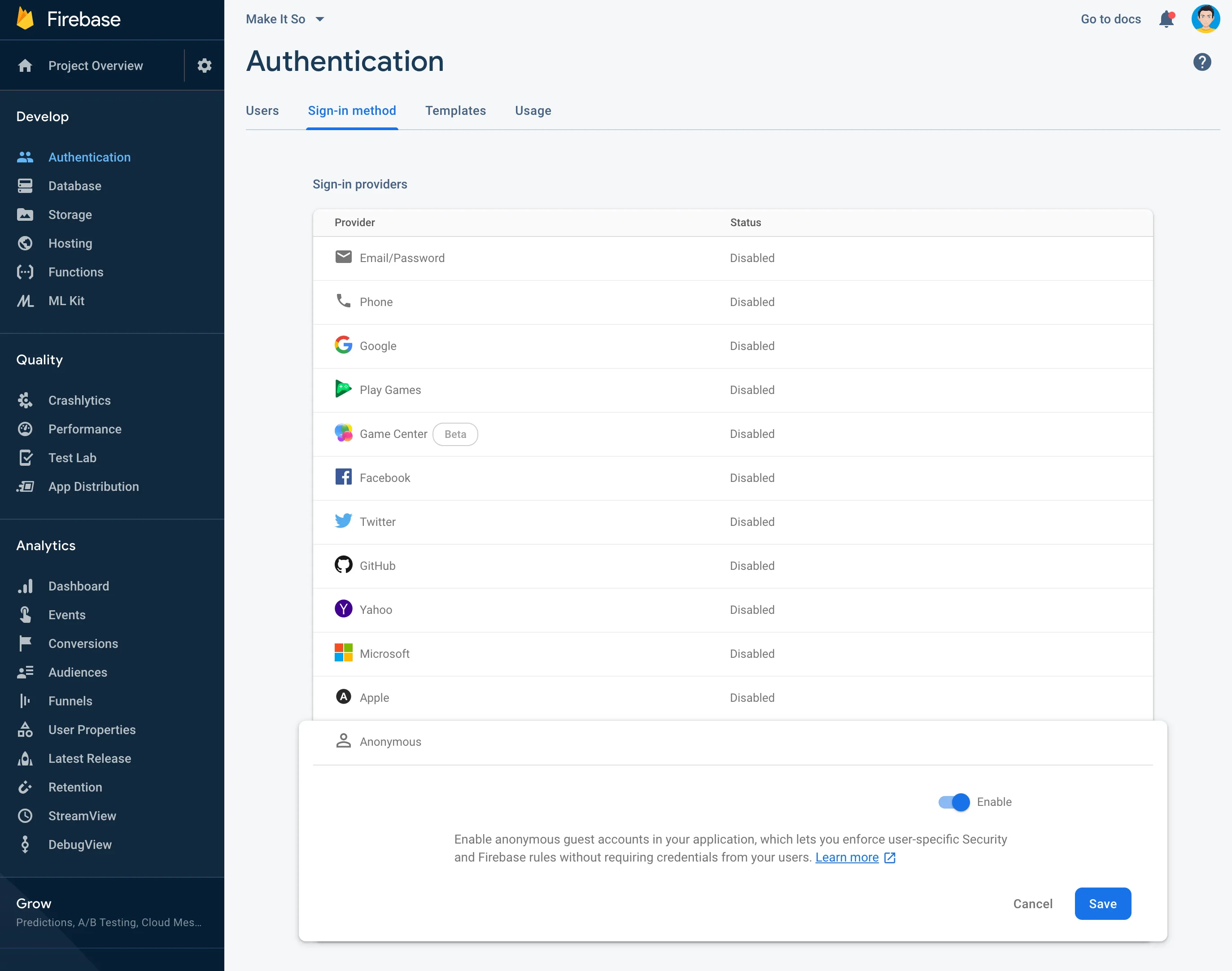
Before we can use Anonymous Auth in our app, we’ll have to add Firebase/Auth to our CocoaPods file:
target 'MakeItSo' do
use_frameworks!
# Pods for MakeItSo
pod 'Resolver'
pod 'Disk', '~> 0.6.4'
pod 'Firebase/Auth'
pod 'Firebase/Analytics'
pod 'Firebase/Firestore'
pod 'FirebaseFirestoreSwift'
endNext, let’s build a simple authentication service to encapsulate handling signing in, signing out, and providing access to the currently signed-in user. By encapsulating all of this in a dedicated service, we’ll later be able to add other authentication mechanisms (such as Sign in with Apple) more easily.
// File: Services/AuthenticationService
import Foundation
import Firebase
class AuthenticationService: ObservableObject {
@Published var user: User? 1
func signIn() {
registerStateListener() 2
Auth.auth().signInAnonymously() 3
}
private func registerStateListener() {
Auth.auth().addStateDidChangeListener { (auth, user) in 4
print("Sign in state has changed.")
self.user = user
if let user = user {
let anonymous = user.isAnonymous ? "anonymously " : ""
print("User signed in \(anonymous)with user ID \(user.uid).")
}
else {
print("User signed out.")
}
}
}
}The service’s user property (1) provides access to the currently signed in Firebase user. By annotating this as a @Published property, we can later use Combine to react to any changes (such as when the user signs in or out) more easily.
When the service’s signIn() method is called, we will register (2) a state listener (4), which is called whenever the user signs in or out. Finally, we ask Firebase Auth to sign in anonymously (3).
As before, we need to register the service with our dependency injection framework in AppDelegate+Injection.swift:
extension Resolver: ResolverRegistering {
public static func registerAllServices() {
register { AuthenticationService() }.scope(application)
register { FirestoreTaskRepository() as TaskRepository }.scope(application)
}
}To initiate the sign-in process, we inject the service into our AppDelegate, and call the signIn method after Firebase has been initialised:
// File: App/AppDelegate.swift
class AppDelegate: UIResponder, UIApplicationDelegate {
@Injected var authenticationService: AuthenticationService
func application(_ application: UIApplication, didFinishLaunchingWithOptions launchOptions: [UIApplication.LaunchOptionsKey: Any]?) -> Bool {
FirebaseApp.configure()
authenticationService.signIn()
return true
}
// code omitted for clarity
}Making the Task Repository User-Aware
Now that we’ve successfully and anonymously signed in our user, we can store the user’s ID in the tasks they create to indicate their “ownership”.
To this end, we first need to add a userId field to the Task struct:
struct Task: Codable, Identifiable {
@DocumentID var id: String?
var title: String
var priority: TaskPriority
var completed: Bool
@ServerTimestamp var createdTime: Timestamp?
var userId: String?
}Then, we’ll have to make a couple of changes to the FirestoreTaskRepository:
class FirestoreTaskRepository: BaseTaskRepository, TaskRepository, ObservableObject {
var db = Firestore.firestore()
@Injected var authenticationService: AuthenticationService 1
var tasksPath: String = "tasks" 2
var userId: String = "unknown"
private var cancellables = Set<AnyCancellable>()
override init() {
super.init()
authenticationService.$user 3
.compactMap { user in
user?.uid 4
}
.assign(to: \.userId, on: self) 5
.store(in: &cancellables)
//(re)load data if user changes
authenticationService.$user 6
.receive(on: DispatchQueue.main) 7
.sink { user in
self.loadData() 8
}
.store(in: &cancellables)
}
private func loadData() {
db.collection(tasksPath)
.whereField("userId", isEqualTo: self.userId) 9
.order(by: "createdTime")
.addSnapshotListener { (querySnapshot, error) in
if let querySnapshot = querySnapshot {
self.tasks = querySnapshot.documents.compactMap { document -> Task? in
try? document.data(as: Task.self)
}
}
}
}
func addTask(_ task: Task) {
do {
var userTask = task
userTask.userId = self.userId 10
let _ = try db.collection(tasksPath).addDocument(from: userTask)
}
catch {
fatalError("Unable to encode task: \(error.localizedDescription).")
}
}
func removeTask(_ task: Task) {
if let taskID = task.id {
db.collection(tasksPath).document(taskID).delete { (error) in
if let error = error {
print("Unable to remove document: \(error.localizedDescription)")
}
}
}
}
func updateTask(_ task: Task) {
if let taskID = task.id {
do {
try db.collection(tasksPath).document(taskID).setData(from: task)
}
catch {
fatalError("Unable to encode task: \(error.localizedDescription).")
}
}
}
}Let’s look at what this code does:
- We use Resolver to inject an instance of
AuthenticationService(1) - All tasks are contained in the
taskscollection, so we define a constant (2) to keep things DRY. - In the initialiser, we subscribe (3) and (6) to the
userpublisher on theAuthenticationServiceto be informed whenever theuserproperty changes. - The first Combine pipeline (3) extracts the user’s ID (4), and assigns it to the
userIdproperty (5) - The second pipeline (6) also kicks in whenever the
userproperty on the authentication service changes. It then invokes theloadData()method (8) to (re)load the current user’s tasks. - It is essential to make sure any update to the UI is executed on the main thread. This can be achieved by using the
.receive(on:)operator (7) - this tells Combine to run the rest of the pipeline from here on on the specified thread/queue. - To make sure we only fetch tasks that belong to the current user, we add a
whereFieldclause, specifying the current user id (9). - When adding a new task, we need to make sure to provide the current user ID - otherwise, the task wouldn’t be in the result set of the query above (9).
When you run the app now, you will see that any tasks you add via the UI disappear from the list view immediately. You might also notice an error message in the Xcode console, indicating that the snapshot listener didn’t yield any results and that you should create an index.
[Firebase/Firestore][I-FST000001] Listen for query at tasks failed: The query requires an index. You can create it here: https://console.firebase.com/v1/r/project/<your-project-id>/firestore/indexes?create_composite=some-random-looking-id
This is due to the fact that we’re now using a compound query: we ask Firestore to query the userId field and sort by the createdTime field. To fulfil the promise that no query is a slow query, Firestore demands that you set up an index for this compound query. By following the link in the error message, you can create this index very easily. In fact, this is the recommended way to create indexes for Firestore!
Finally
If you’re following along, check out the tag
stage_3/finish_line and open
MakeItSo.xcworkspace in the final folder]
To verify your implementation, launch the application on a Simulator. When the UI comes up, the task list should be empty, and the Xcode console should indicate the user ID of the anonymous user you just signed in with.
Open the Firebase console side-by-side with the Simulator, and navigate to the Firestore database browser so you can observe the database updating as you add new items to the task list (you might need to reload the browser window once): any new items will be inserted as child documents under the tasks collection of your user ID.
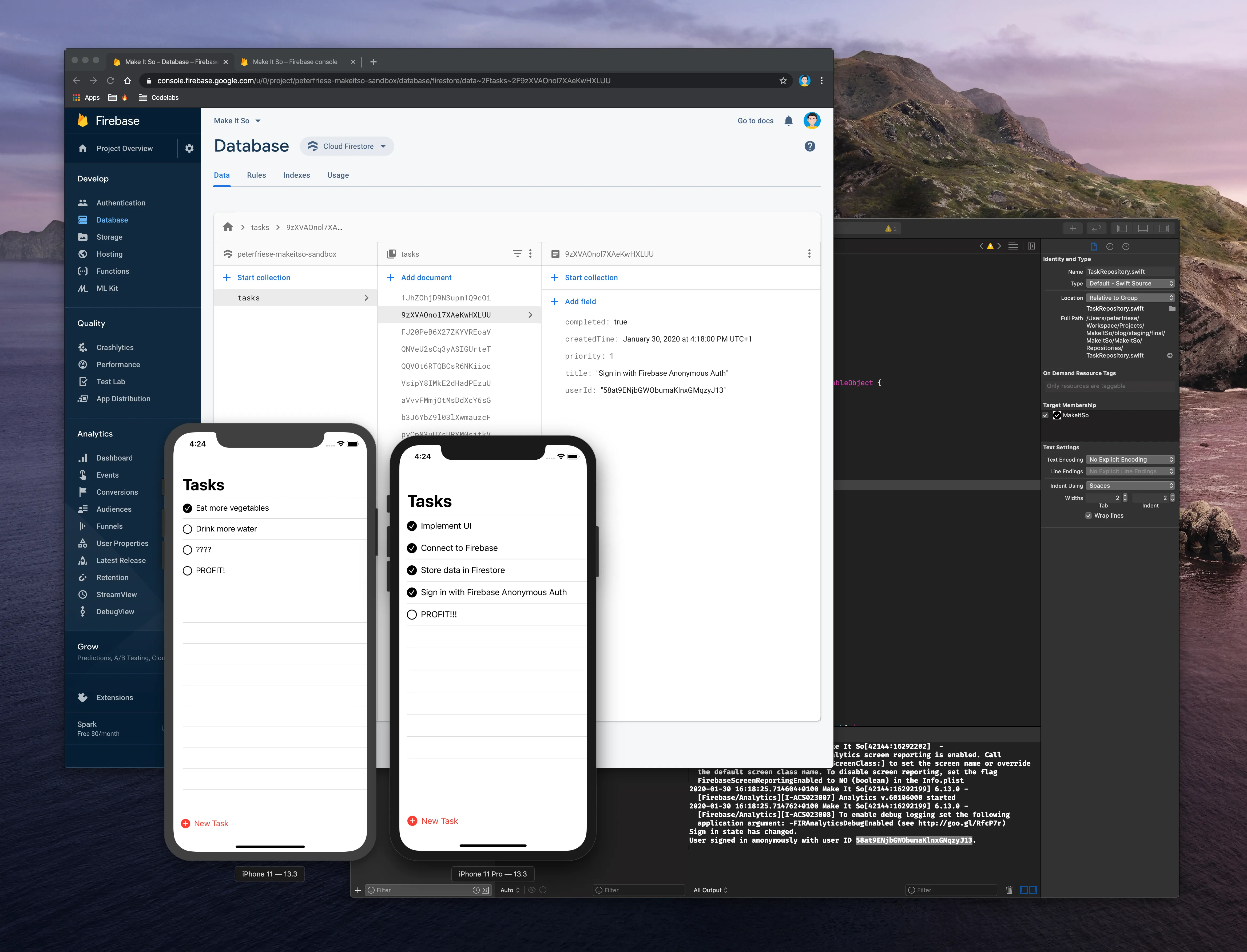
If you start the application on another device (Simulator or physical phone), you will notice that this will result in a new user document being created under the users collection. Both users can change their data independently of each other - just like we wanted.
In the screenshot below, you can see that each of the simulators has been assigned a different user ID, and if you look closely, you will see that the user ID 58at9ENjbGWObumaKlnxGMqzyJ13 (displayed in the Xcode console) makes an appearance in the Firestore data browser as well.
We need to talk about security
No article about Cloud Firestore would be complete without mentioning Security Rules! Earlier, when setting up the Firestore database for your project, I told you to choose the development settings. This made it easy to get started, because our clients could read and write data from and to the database. However, there is a huge issue: anyone can access your database - they just have to guess your project ID. To prevent malicious people on the internet from tampering with your users’ data, we need to set up some security rules. You can add security rules to your Cloud Firestore database by navigating to the Rules tab in the Cloud Firestore database browser in the Firebase Console.
Without further ado, here are some initial security rules that might start to secure our database:
rules_version = '2';
service cloud.firestore {
match /databases/{database}/documents {
match /tasks/{task} {
allow write: if request.auth.uid != null
&& request.resource.data.userId == request.auth.uid; //(1)
allow read: if resource.data.userId == request.auth.uid; //(2)
}
}
}
To secure our database, we need to make sure that only registered users can create new tasks, and that users can only read the tasks they own (i.e. the ones they created).
By demanding that a write request must contain a valid authentication object (1), we ensure only signed in users can create new tasks.
The second requirement can be met by comparing the userId field of the task that is being requested with the user ID of the incoming read request. Only if they match up, the read request is permitted.
And with that, our database on its way to being more secure.
Conclusion
In this article, you saw how easy it is to
- Add Firebase to your existing iOS project
- Store user data in Cloud Firestore
- Use Firebase Anonymous Authentication to transparently sign in your users
Thanks to implementing MVVM and using a dependency injection framework like Resolver, we’ve established a flexible architecture that has already made it easy to change some of the app’s components without massive refactorings.
In the next episode, we’re going to look at Sign in with Apple, how to add a sign-up flow to the app without disrupting the user experience, and how Firebase can make this easier for us.
Thanks for reading!
Resources

Agentic Coding in Xcode with Gemini CLI
Build apps with AI assistance in Xcode using Gemini CLI

Turn Your Photos Into Miniature Magic with Nano Banana
Build stunning image generation apps in iOS with just a few lines of Swift

Reverse-Engineering Xcode's Coding Intelligence prompt
A look under the hood

Extracting structured data from PDFs using Gemini 2.0 and Genkit
Understanding SwiftUI Preferences
SwiftUI Parent / Child View Communication